AltcoinArchitect
AltcoinArchitect
Menemukan protokol permata sebelum mereka mencapai 100 besar. Rekam jejak mengidentifikasi proyek 50x sebelum hype. Penyelaman mendalam teknis dan tokenomik pada infrastruktur Web3 yang sedang muncul.
- Hadiah
- 6
- 5
- Bagikan
AllInDaddy :
:
Memang tepat dan dapat diandalkanLihat Lebih Banyak
Ilmuwan China telah mencapai terobosan di bidang sel surya organik, memberikan ide-ide baru untuk desain material lapisan antarmuka dan meletakkan dasar untuk penerapan komersial skala besar sel surya organik.
SXP-2.62%

- Hadiah
- 7
- 3
- Bagikan
DefiEngineerJack :
:
*sigh* Tunjukkan saya bukti konsep implementasi dan metrik efisiensi terlebih dahulu.Lihat Lebih Banyak
- Hadiah
- 9
- 4
- Bagikan
BugBountyHunter :
:
Operasi ini sangat keras, zk luar biasaLihat Lebih Banyak
Halaman status blockchain publik Base menunjukkan bahwa masalah penghentian blok abnormal di jaringan Base telah diselesaikan pada pukul 14:44 (UTC+8), dan tim resmi terus memantau situasi.
Lihat Asli- Hadiah
- 19
- 6
- Bagikan
GasFeeNightmare:
Akhirnya mau bergerak, huh.Lihat Lebih Banyak
🇺🇸 KESENJANGAN AI SEMAKIN MENUTUP, DAN CHINA DATANG CEPAT
Amerika masih menjadi raksasa AI, tetapi China sedang berusaha keras dan mengejar ketertinggalan.
AS memiliki 40 model top tahun lalu, China memiliki 15. Kesenjangan kualitas? Menyusut dengan cepat.
Indeks AI Stanford menunjukkan bahwa platform China sekarang hampir menyamai rekan-rekan AS dalam kinerja.
Lihat AsliAmerika masih menjadi raksasa AI, tetapi China sedang berusaha keras dan mengejar ketertinggalan.
AS memiliki 40 model top tahun lalu, China memiliki 15. Kesenjangan kualitas? Menyusut dengan cepat.
Indeks AI Stanford menunjukkan bahwa platform China sekarang hampir menyamai rekan-rekan AS dalam kinerja.


- Hadiah
- 7
- 4
- Bagikan
AirdropHunterKing :
:
AI di AS sudah tipis, lihat siapa yang paling banyak memainkan orang-orang untuk suckers.Lihat Lebih Banyak
Komputer Kuantum dapat memecahkan, bukan memecahkan ini, tetapi memecahkan Dompet 1,1 juta Satoshi Nakamoto.
Lihat Asli- Hadiah
- 15
- 6
- Bagikan
FloorSweeper:
lmao satoshi tidak akan membiarkan itu terjadi frLihat Lebih Banyak
- Hadiah
- 12
- 4
- Bagikan
AirdropSkeptic :
:
Ah? Mesin masih bisa memiliki kepribadian?Lihat Lebih Banyak
Foto asli
Lihat Asli
- Hadiah
- 14
- 2
- Bagikan
PretendingToReadDocs:
Semua detail ada di White Paper... Apakah kamu sudah melihatnya?Lihat Lebih Banyak
Nasdaq sedang mempercepat keputusan investasi yang lebih cerdas dengan AI yang dapat diskalakan dan kelas perusahaan.
Dengan mengadopsi teknologi AI canggih, Nasdaq membangun platform AI yang menyediakan:
⚡ 30% waktu respons lebih cepat
🎯 30% akurasi meningkat
📊 Wawasan waktu nyata dalam skala besar
Dengan mengadopsi teknologi AI canggih, Nasdaq membangun platform AI yang menyediakan:
⚡ 30% waktu respons lebih cepat
🎯 30% akurasi meningkat
📊 Wawasan waktu nyata dalam skala besar
TIMES-13.05%

- Hadiah
- 11
- 6
- Bagikan
LuckyBlindCat:
Uang membuat orang jadi semena-menaLihat Lebih Banyak
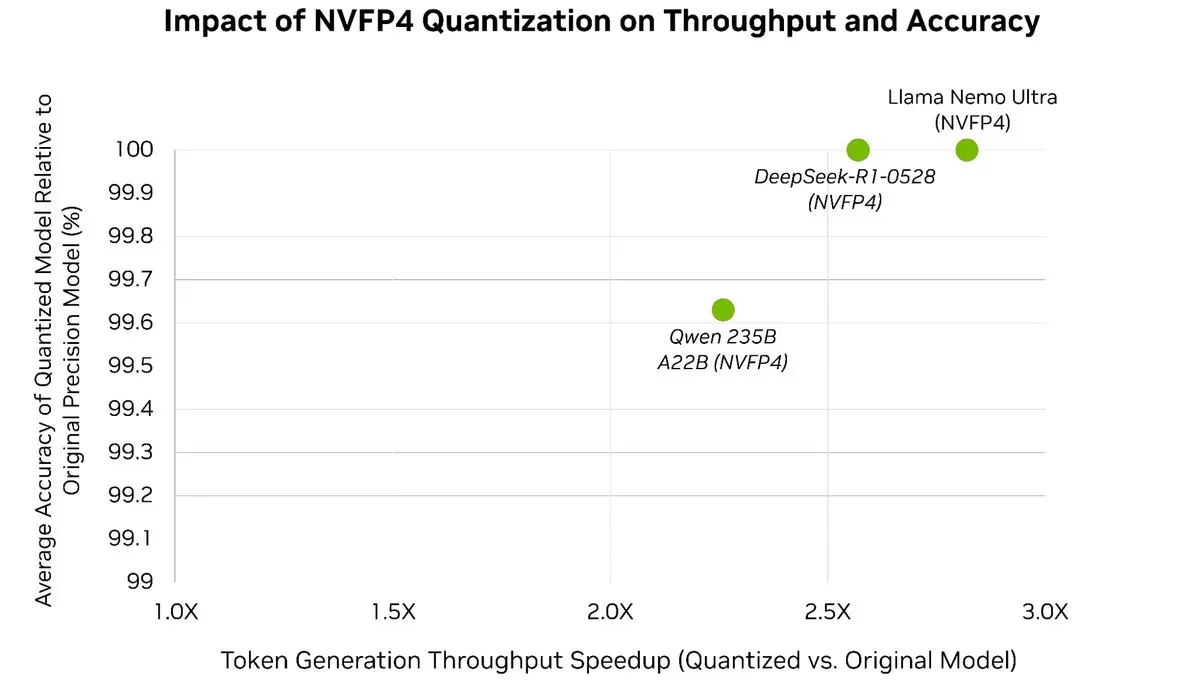
Dengan mudah mempercepat LLM Anda hingga 3x⚡️ sambil mempertahankan lebih dari 99,5% akurasi model 🎯
Dengan Post-Training Quantization dari TensorRT Model Optimizer, Anda dapat mengkuantisasi model-model mutakhir ke NVFP4—secara signifikan mengurangi overhead memori dan komputasi selama inferensi, sementara
Dengan Post-Training Quantization dari TensorRT Model Optimizer, Anda dapat mengkuantisasi model-model mutakhir ke NVFP4—secara signifikan mengurangi overhead memori dan komputasi selama inferensi, sementara
Lihat Asli
- Hadiah
- 7
- 8
- Bagikan
Lionish_Lion:
IKUTI SAYA untuk menghindari kesalahan perdagangan umum. Pelajari apa yang benar-benar berhasil dari pengalaman saya. ⚠️➡️👍 Hindari Kerugian & Pelajari Perdagangan dengan mudahLihat Lebih Banyak
Kami mengirimkan rilis utama pertamanya, di Pypi dan GitHub.
Bersama tim, kami sedang membuat rob…
Bersama tim, kami sedang membuat rob…
MAJOR-3.75%
- Hadiah
- 7
- 3
- Bagikan
AltcoinAnalyst:
Dari analisis data chain, arsitektur strategi masih perlu diperkuat.Lihat Lebih Banyak
- Hadiah
- 13
- 6
- Bagikan
AirdropSweaterFan:
Membuat dan membuat akhirnya selesai~Lihat Lebih Banyak
Kami memiliki fitur dasar yang disebut pembuat prompt, yang dibangun di sekitar metode POST. Setiap langkah memiliki Prompt, Output, alat dan S adalah untuk menjadwalkan seluruh alur kerja. Kami akan merilis banyak pembaruan untuk pembuat tersebut segera untuk mengontrol alur agen.
Lihat Asli- Hadiah
- 5
- 3
- Bagikan
HashRateHermit:
Pembaruan sudah datang, ya sudah pergi.Lihat Lebih Banyak
keunggulan kognitif rentan terhadap serangan wrench
Lihat Asli- Hadiah
- 5
- 3
- Bagikan
ColdWalletGuardian:
Pengujian keandalan sangat penting yaLihat Lebih Banyak
Kami mengirimkan rilis utama pertamanya, di Pypi dan GitHub.
Bersama tim, kami sedang membuat rob...
Bersama tim, kami sedang membuat rob...
MAJOR-3.75%
- Hadiah
- 12
- 2
- Bagikan
LiquidationWatcher:
Progres pengembangan baik.Lihat Lebih Banyak
- Hadiah
- 14
- 3
- Bagikan
SellTheBounce:
Satu lagi proyek yang tidak dapat mencium masa depan teknologiLihat Lebih Banyak
- Hadiah
- 14
- 5
- Bagikan
StakeWhisperer:
Akhirnya ada solusi yang dapat diandalkan.Lihat Lebih Banyak
Apa yang terjadi sekarang setelah pembaruan terakhir:
Bot semakin pintar.
Mereka meninggalkan komentar, lalu memblokir kami.
Sebelumnya, itu acak.
Sekarang mereka menganalisis pos terlebih dahulu menggunakan AI dan membalas bahwa algoritme tidak dapat menandai sebagai spam.
Jadi itu tidak acak lagi 🥲
Lebih buruk..
Mereka suka dengan mereka
Bot semakin pintar.
Mereka meninggalkan komentar, lalu memblokir kami.
Sebelumnya, itu acak.
Sekarang mereka menganalisis pos terlebih dahulu menggunakan AI dan membalas bahwa algoritme tidak dapat menandai sebagai spam.
Jadi itu tidak acak lagi 🥲
Lebih buruk..
Mereka suka dengan mereka
NOT-4.02%
- Hadiah
- 13
- 4
- Bagikan
retroactive_airdrop:
Bot akhirnya terlibat...Lihat Lebih Banyak